Single-particle diffusional fingerprinting
Overview
Single-particle tracking(SPT)으로 얻은 분자 궤적(trajectory)을 분류하고 해석하기 위한 머신러닝 프레임워크. “Diffusional fingerprint”란 각 궤적에서 추출한 17개의 특성 분포로, 이것을 이용해 입자의 종류를 분류하고 확산 메커니즘에 대한 물리적 통찰을 얻는다.
핵심 아이디어: 기존 방법들은 특정 확산 모델(e.g., anomalous diffusion, confined diffusion)을 사전에 가정해야 했지만, diffusional fingerprinting은 모델-무관(model-agnostic)하게 작동한다.
The main benefit of a fingerprinting approach compared to model-based analysis is that it does not require an a priori assumption of the type of diffusion.
또한 시뮬레이션 데이터로 pretrain할 필요 없이, 실험 데이터 자체를 학습/예측에 사용한다.
→ 17개의 특성을 이용해 ‘이 입자는 이런 diffusion dynamics를 가지고 있다! ’ 라는 걸 제시하는것 까지는.. 이 논문에서 바라지 않는다. 그저 서로 다른 diffusion dynamics를 구별할 수 있는 지표를 제공한다.
Link to PDF and DOI
- DOI: 10.1073/pnas.2104624118
- PDF: single-particle-diffusional-fingerprinting-a-machine-learning-framework-for-quantitative-analysis-of.pdf
- Supporting data: S_single-particle-diffusional-fingerprinting.pdf
주요 내용 요약
방법론: 17개 Feature 추출
각 궤적에서 아래 4가지 범주의 feature를 계산한다:
1. HMM (Hidden Markov Model) features
- 4-state HMM을 전체 궤적에 global fitting
- 각 state의 체류 시간:
, 평균 체류 시간 - State-shifting(속도 전환) 확산을 포착하는 데 핵심적
2. MSD scaling features
- Power law fit to MSD:
- 추출 feature:
(anomalous exponent), (diffusion constant), MSDratio, Pval
3. Trajectory shape features
- kurtosis, dimension (fractal dimension), efficiency, trappedness
- 운동의 지속성(persistence)과 갇힘(confinement) 포착
4. Step statistics
- Gaussianity (non-Brownian displacement 검출)
- meanSL (average step length), meanMSD, N (track length)
전체 Feature 목록 및 설명
| Feature | Description |
|---|---|
| Time in the slowest diffusion state | |
| Time in the second slowest diffusion state | |
| Time in the second fastest diffusion state | |
| Time in the fastest diffusion state | |
| Average residence time in a diffusion state | |
| meanSL | Average step length for the trace |
| Pval | Quality of a power law fit to the MSD curve |
| MSD power law scaling coefficient ( | |
| Diffusion constant from power law fit | |
| Trappedness | Estimates whether the walker is trapped ( |
| meanMSD | Intermediate time spread of the trajectory |
| Kurtosis | Heaviness of the tails in the distribution of points in the entire trajectory ( |
| Gaussianity | Heaviness of the tails of the distribution for the steps ( |
| Fractal dimension | Space-filling-ness of the trajectory (slightly less than 2 for Brownian motion) |
| Efficiency | Linearity of the trajectory ( |
| MSD ratio | MSD power law scaling coefficient from trajectory statistics, not fit ( |
| Bleaching rate or binding affinity to the substrate |
분류 파이프라인
- 각 궤적 → 17개 feature 계산
- Linear Discriminant Analysis (LDA)로 feature ranking
- Logistic regression으로 입자 identity 분류
- 상위 feature 해석 → 물리적/메커니즘적 통찰
검증: 시뮬레이션 데이터
- Speed-switching (fast vs slow HMM): F1 = 95.7 ± 0.4%
- 주요 discriminating features:
, meanSL
- 주요 discriminating features:
- Anomalous diffusion (subdiffusive
, normal , superdiffusive ): F1 = 92.1 ± 0.4% - 주요 features: MSDratio, Dimension, alpha, Trappedness
- CNN(state-of-the-art)과 비슷한 성능, 하지만 feature ranking으로 mechanistic insight 제공
실험 데이터 적용
1. TLL Lipase (L3 vs native)
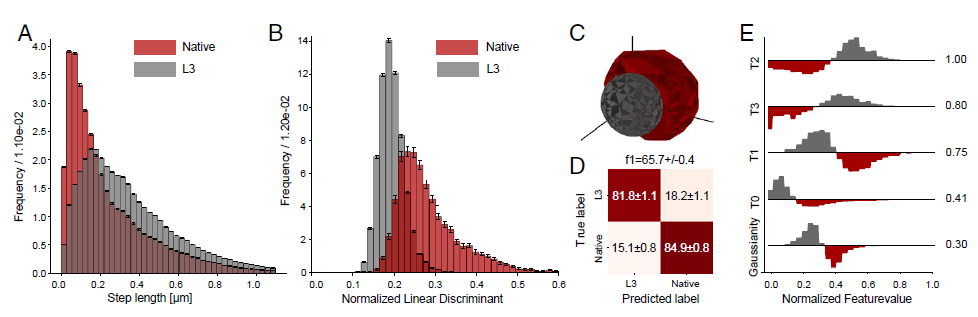
- 촉매 효율은 거의 동일하나, step-length 분포가 overlap 되어 원래는 분류하기 까다로운 두 분자 → fingerprinting으로 분리 가능 (F1 = 65.7%)
- LDA 상위 feature: L3는 빠른 state(
, )를 더 많이 점유, native는 느린 state( , )를 더 많이 점유 - 핵심 해석 체인:
- Product inhibition: 효소가 반응을 촉매하면 생성물(product)이 주변에 쌓임. 이 생성물이 효소 활성 부위에 다시 결합하면 효소 활성을 저하하는 product inhibition이 발생한다.
- Chemotaxis vs Antichemotaxis: chemotaxis는 화학 농도 기울기를 따라 이동하는 현상. 반대로 antichemotaxis는 생성물 농도가 높은 곳에서 멀어지는 방향으로 이동 → 방금 반응한 자리를 탈출.
- L3의 large jump → antichemotaxis: L3가 stochastically 큰 점프를 한다는 것은, 반응 후 생성물이 쌓인 자리에서 멀리 이탈한다는 의미 → product 농도가 낮은 새 자리에서 반응 재개 → product inhibition 회피.
→ 얼마 전에 저널 클럽에서 소개된 ‘맥스웰의 악마’ 논문이 생각남 Journal reading - Enzyme as Maxwell’s Demon - 실험적 검증: 실제로 L3는 bulk product inhibition이 낮다는 게 기존 실험(ref. 19)에서 확인됨 → fingerprinting이 제시한 메커니즘 가설을 뒷받침
- 이 분석은 fingerprinting이 단순 분류를 넘어 기존에 몰랐던 메커니즘적 통찰을 새롭게 도출한 대표적 예시
2. Transcription factors in cells (Sox2 vs NLS)
- Sox2: 중간 확산계수, mouse embryonic stem cell
- NLS: 더 빠른 확산, 낮은 DNA 결합 친화도
- F1 = 72.7%, NLS 91% / Sox2 52% (NLS 내 두 population 존재)
3. Nanoparticles in mucus (PLGA vs TPGS-coated)
- TPGS coating이 mucus 투과성 향상
- F1 높음: TPGS 93%, PLGA 91%
- TPGS: 더 빠르고, less confined, more Brownian (
, fractal dim ≈ 2) - 해석: PLGA가 mucus channel에 갇혀 subdiffusive → TPGS coating이 이를 해제
Questions & Insights
-
Q: 왜 일반 Markov model이 아니라 Hidden Markov Model을 쓰는가?
A: SPT에서 실제로 관측하는 건 분자의 위치(좌표)뿐이고, 분자가 어떤 내부 state(빠름/느림/갇힘 등)에 있는지는 직접 보이지 않는다. state는 hidden이고 displacement만 observed이기 때문에 HMM이 필요하다. 일반 Markov model은 state를 직접 관측할 수 있다고 가정하므로 SPT에 적합하지 않다. -
Q: 4-state HMM의 가정은 무엇인가?
A: (1) Markov property: 현재 state는 바로 직전 state에만 의존.. (2) Gaussian emission: 각 hidden state 에서 관측되는 displacement는 를 따름. 즉 각 state는 고유한 확산계수 를 가진다. -
Q: 왜 하필 4개의 state인가?
A: 논문이 4를 엄밀하게 최적화한 것은 아니다. 실용적 이유: 생물학적 확산의 다양한 속도 레짐(bound/free, fast/slow 등)을 포착하기에 충분하면서, 모든 시스템에 동일하게 적용할 수 있는 범용 표현이 됨. 2-state는 너무 단순하고, state가 너무 많으면 overfitting + 계산 부담이 커진다. -
Q: 각 state에 체류하는 시간
를 어떻게 알아내는가?
A: 두 단계로 구성됨. (1) Baum-Welch (EM): 모든 궤적 데이터를 global하게 사용해 전이 확률와 각 state의 를 학습. (2) Viterbi algorithm: 학습된 파라미터로 각 궤적의 “가장 그럴듯한 state sequence”를 복원 ( ). 이 Viterbi path에서 state 에 연속으로 머문 구간들의 평균 길이가 체류 시간 가 된다. -
Q: MSD scaling feature인
, , MSDratio, Pval은 각각 무엇을 의미하며 왜 묶여 있는가?
A: 이 4개는 모두 MSD curve에 power law를 fit하는 단 하나의 과정에서 나오는 결과들이다. (anomalous exponent)는 확산의 “스타일” — 이면 subdiffusion(갇힘), 이면 normal Brownian diffusion, 이면 superdiffusion(directed motion). 는 확산의 전반적인 “속도”. MSDratio는 short-time MSD와 long-time MSD의 비율로, confinement의 독립적 신호를 제공함(갇힌 분자는 장기 MSD가 포화되므로 비율이 작아짐). Pval은 power law fit의 통계적 유의성 — “이 모델이 얼마나 잘 맞는가”라는 메타정보 자체가 분자 dynamics의 복잡성을 나타내는 feature가 된다. -
Q: 왜 PCA가 아니라 LDA를 쓰는가? 둘의 차이는 무엇인가?
A: 한 줄 핵심: PCA는 “데이터를 가장 잘 설명하는” 방향을 찾고, LDA는 “집단 간 차이를 가장 잘 드러내는” 방향을 찾는다. PCA는 label을 모른 채 분산이 최대인 방향를 찾는다( ). 반면 LDA는 label을 알고, between-class scatter (집단 간 거리)를 키우고 within-class scatter (집단 내 퍼짐)를 줄이는 방향을 찾는다( , Fisher’s discriminant). 데이터를 가장 많이 설명하는 방향이 집단을 가장 잘 구분하는 방향과 다를 수 있기 때문에, classification이 목적이라면 LDA가 적합하다. 직관적으로 LDA는 “classification 목적으로 PCA를 돌리는 것”과 유사하다. 이 논문에서 PCA는 3D 시각화(fingerprint 분리도 확인)에만 쓰이고, LDA는 feature ranking + 1D projection(실제 분류 및 메커니즘 해석)에 쓰인다 — LDA 해의 각 성분 가 feature 의 집단 분리 기여도를 나타내므로 ranking이 자동으로 나온다. -
Q: F1 score는 무엇을 나타내는 값인가? 왜 accuracy 대신 쓰는가?
A: F1 score는 Precision(내가 양성이라 예측한 것 중 실제 양성 비율,)과 Recall(실제 양성 중 내가 맞힌 비율, )의 조화평균이다: . 조화평균의 핵심 성질상 둘 중 하나라도 낮으면 F1이 확 낮아진다. 단순 accuracy는 클래스 불균형에 취약하다 — 예컨대 L3(68,200개) vs native(5,630개) 데이터에서 모든 것을 L3로 예측해도 accuracy ≈ 92%가 나오지만, recall이 0이라 F1은 낮게 나온다. 논문에서 TLL lipase의 F1(65.7%)이 각 클래스 accuracy(81.8%, 84.9%)보다 낮은 것도 이 불균형 때문이며, F1이 더 정직한 지표다. 3개 이상 클래스에서는 클래스별 F1의 평균(macro/weighted F1)을 사용한다. -
Q: 2D Brownian motion에서 step length의 분포는 Gaussian인가? Rayleigh인가? 둘의 차이는?
A: Displacement(변위,또는 ) 는 Gaussian을 따르지만, step length( ) 는 Rayleigh 분포를 따른다: . Gaussian과 달리 앞에 이 곱해지는 이유는 기하학적 효과 때문 — 반지름 에서 사이의 annulus 넓이가 로 에 비례하므로 Gaussian 확률밀도에 면적 factor 이 곱해진다. 논문이 HMM emission으로 Rayleigh 대신 Gaussian을 사용하는 이유: 실제 확산 모델을 fit하는 게 목적이 아니라 “속도 레짐 분리”가 목적이기 때문. Rayleigh는 꼼리가 넓어 state 경계가 흐릿하지만, Gaussian은 더 localized되어 있어 빠른/느린 state를 더 선명하게 구분한다. 직관: displacement 성분은 Gaussian, step length은 성분 Gaussian 두 개를 제곱합한 후 제곱근을 취한 것이라 다른 종류의 분포로 변환된다. -
Q: 카메라 프레임 간격(temporal resolution)이 달라지면 같은 Brownian motion이 다른 확산처럼 보일 수 있는가?
A: 맞다. 분자가 빠른/느린 state를 전환하는 timescale을라 할 때, 세 가지 극단이 있다. (1) 프레임 간격 : state 전환이 포착됨 → heterogeneous state-switching diffusion으로 보임. (2) 프레임 간격 : 한 프레임 동안 수많은 전환이 평균화 → 유효 확산계수 를 따르는 단일 Brownian motion처럼 보임. (3) 프레임 간격 : 전환이 일부만 평균화 → MSD curve가 꺾여 겉보기 subdiffusion( )처럼 보일 수 있음. 실제론 normal diffusion인데도. 이 때문에 diffusional fingerprinting의 feature들( , MSDratio, 등)은 모두 temporal resolution에 의존하며, 논문이 시뮬레이션 pretraining 없이 실험 데이터로 직접 train/predict하는 이유 중 하나가 바로 이 temporal resolution 불일치 문제를 피하기 위해서다.
Related Concepts
이 논문을 이해하기 위해 필요한 학습 노트를 연결한다.
글리아와 논문을 읽으며 새로 공부하고, 작성한 학습노트를 이곳에 자동으로 추가한다.
17개 Feature 상세 (Supplementary 기반)
17개 feature는 4개 범주로 묶인다. 아래에 각 feature의 수식과 물리적 의미를 정리한다.
범주 A. HMM Features:
4-state HMM (Gaussian emission)을 모든 궤적의 step length에 global fitting한 뒤, 각 궤적에 Viterbi algorithm을 적용해 가장 그럴듯한 state sequence를 복원한다.
: 가장 느린 state에서 보낸 시간 비율 : 두 번째로 느린 state 체류 비율 : 두 번째로 빠른 state 체류 비율 : 가장 빠른 state 체류 비율 : 궤적 전체에서의 평균 state 체류 시간
왜 step length 분포가 아닌 Gaussian을 emission으로 쓰나?
HMM의 목적이 실제 확산 모델을 fit하는 게 아니라 궤적의 “속도 레짐”을 대략적으로 포착하는 것이기 때문. Gaussian은 step length의 실제 분포(Rayleigh)보다 더 localized되어 있어 state 구분에 유리하다.
범주 B. MSD Scaling Features:
MSD curve에 power law를 fit하는 하나의 과정에서 나오는 4개의 결과:
(anomalous exponent): 확산의 “스타일”. 이면 subdiffusion(anti-persistent, 갇힘), 이면 normal Brownian diffusion, 이면 superdiffusion(persistent, directed) (diffusion constant): 전반적인 이동 속도 (일반화된 확산계수) - Pval: power law fit의
검정 p-value. fit이 잘 맞을수록 높음. “이 궤적이 얼마나 깔끔한 power law를 따르는가”라는 메타정보 자체가 feature - MSDratio: MSD curve의 형태를 두 점에서 직접 추정 (fit 없이):
normal diffusion이면 0, superdiffusion이면 양수, subdiffusion이면 음수. power law fit의
범주 C. Trajectory Shape Features: Trappedness, Kurtosis, Gaussianity, Fractal dimension, Efficiency
Trappedness — 분자가 갇혀 있을 확률:
Trappedness가 크다 →
Kurtosis — 궤적의 공간 분포 가 Gaussian 대비 얼마나 heavy-tailed인지. 궤적 좌표의 공분산 행렬(gyration tensor)에서 최대 eigenvalue 방향으로 투영한 1D 분포
Brownian motion에서
Gaussianity — step 분포 가 Brownian과 얼마나 다른지 (단일 프레임 스케일의 step 분포). quartic moment와 second moment의 비율:
Brownian motion에서
Fractal dimension — 궤적이 공간을 얼마나 빽빽하게 채우는지 (Katz-George estimator):
: 직선 (ballistic) : Brownian motion : subdiffusion (confined, 공간 재방문 과다)
Efficiency — 시작-끝 거리 vs 전체 이동 거리의 비율 (직진성):
Brownian motion에서
범주 D. Step Statistics: meanSL, meanMSD, N
- meanSL: 평균 step length. 전반적 속도의 가장 직접적 지표. 짧은 궤적에서 HMM feature보다 robust
- meanMSD: 중간 time scale에서의 궤적 spreading. MSD curve 전체에 power law를 fit해서 얻는
, 와 달리, fit 없이 중간 time lag에서의 MSD 값 하나를 직접 읽는다. 와 는 궤적이 짧으면 데이터 포인트가 부족해 fit이 불안정해지지만, meanMSD는 fit이 없으므로 짧은 궤적에서도 상대적으로 안정적이다. 다른 MSD-derived feature들이 흔들릴 때 “이 궤적이 전반적으로 얼마나 퍼졌는가”를 보완하는 anchor 역할. - N (track duration): 궤적 길이(프레임 수). TIRF 등 surface-based tracking에서 결합 kinetics 및 bleaching rate 정보를 담음
요약 테이블
| Feature | 범주 | Brownian 기준값 | 포착하는 것 |
|---|---|---|---|
| HMM | — | state-switching 속도 분포 | |
| HMM | — | 평균 state 체류 시간 | |
| MSD | 1 | 확산 스타일 (sub/normal/super) | |
| MSD | — | 전반적 속도 | |
| MSDratio | MSD | 0 | confinement/directionality (fit-free) |
| Pval | MSD | — | power law 적합도 |
| Trappedness | Shape | 0.5 | 갇힘 확률 |
| Kurtosis | Shape | 2 | 공간 분포 heavy-tailedness |
| Gaussianity | Shape | 1 | step 분포의 Brownian 유사도 |
| Fractal dimension | Shape | ~2 | 궤적의 공간 충전도 |
| Efficiency | Shape | ~−7 | 직진성/방향성 |
| meanSL | Step stats | — | 평균 속도 |
| meanMSD | Step stats | — | 전반적 spreading |
| N | Step stats | — | 결합 kinetics / bleaching rate |
더 읽어보고 싶은 레퍼런스
이 논문의 레퍼런스 중에서 읽어보고 싶은 것을 링크.