Transient power-law behaviour following induction distinguishes between competing models of stochastic gene expression
왜 이걸 읽었나?
요즘 확률적 유전자 발현에 관한 논문을 좀 찾아보고 있다.
확률 모델을 사용한다는 점과 power-law를 좋아한다는 점에서 이 논문은 우리 랩에서 하는 접근법과 어느 정도 비슷하다.
거기다 생물학적 배경과 물리적 이론이 적당하게 섞여 있다.
저자가 제시하는 새로운 분석법을 chemical master equation 기반으로 해석적으로 한 번 풀고, chemical network simulation을 통해 1차 검증하고, 실제 생물학 실험 데이터와 fitting해서 깔끔하게 검증했다.
(역시 이 정도는 되어야 Nature Communications에 올릴 수 있나 보다.)
저자들의 전공도 주목할 만하다. 에든버러 대학 분들이 쓰셨는데, 두 분은 생물학과 소속이시고 한 분(Martin R. Evans)은 물리천문학과 교수님이시다. 구글 스칼라에 찾아보니 비평형 통계역학 이론을 하시는 분이고, stochastic resetting 관련으로 논문을 많이 내셨으며(Diffusion with stochastic resetting, 2011), 생물학 하시는 분들과 협업도 많이 하시는 것 같다.
여러 모로 이런 논문의 연구 맥락을 닮고 싶다고 생각했다.
제목이 무슨 뜻인가?
Transient power-law behaviour: 세포 집단의 mRNA 수 평균값
following induction: 세포에게 특정 신호나 스트레스를 주어 특정 유전자의 mRNA 전사를 유도(induction)했다는 뜻이다. 시간
competing models of stochastic gene expression: 이 논문의 분석 방법(멱함수 지수 측정)이 서로 경쟁하는 확률적 유전자 발현 모델들을 구별할 수 있다는 뜻이다. 구체적으로, 전사가 일어나기 전 mRNA 생성 기작이이 거쳐야 하는 상태의 수
N-state model
stochastic gene expression model은 mRNA를 만드는 기작이
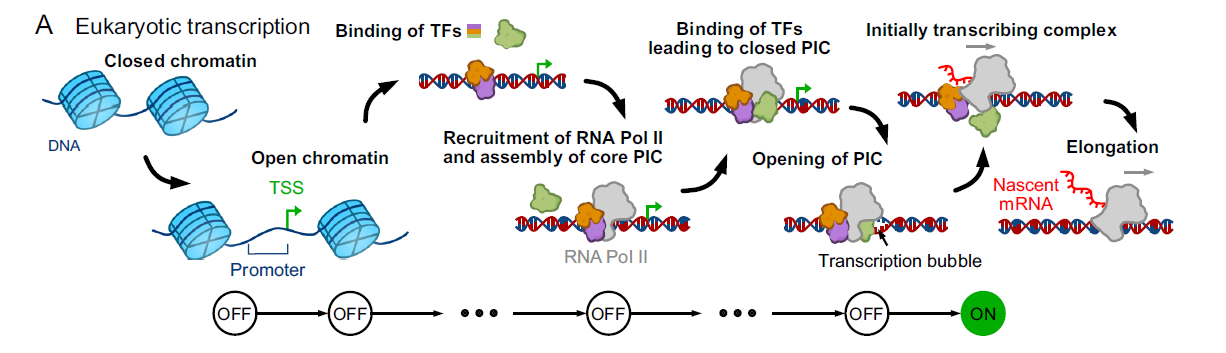
‘mRNA를 만드는 기작’이라는 것은, 아래 그림처럼 유전자가 있는 DNA 부분을 노출 시키고, transcription factor가 DNA에 붙고, RNA polymerase가 가동을 시작하는 그 모든 상태를 의미한다.
| Symbol | Meaning |
|---|---|
| Gene state | |
| Transition rate from | |
| Transition rate from | |
| mRNA concentration | |
| mRNA synthesis rate | |
| mRNA degradation rate | |
| Total number of gene states | |
위 chemical network에서 상태
Overview
이 논문은 확률론적 유전자 발현(stochastic gene expression) 모델들을 구별하는 새로운 방법을 제시한다. 바로 유전자 유도 직후 시간에 따른 mRNA 농도의 평균값(cell average)을 power law로 fitting해서 exponent를 알아내는 것이다.
논문이 다루는 주제는 크게 두 가지이다.
하나는 기존 분석 방법이 잘못되었다고 지적하는 것,
다른 하나는 자신들의 방법이 더 좋다는 것을 보이는 것이다.
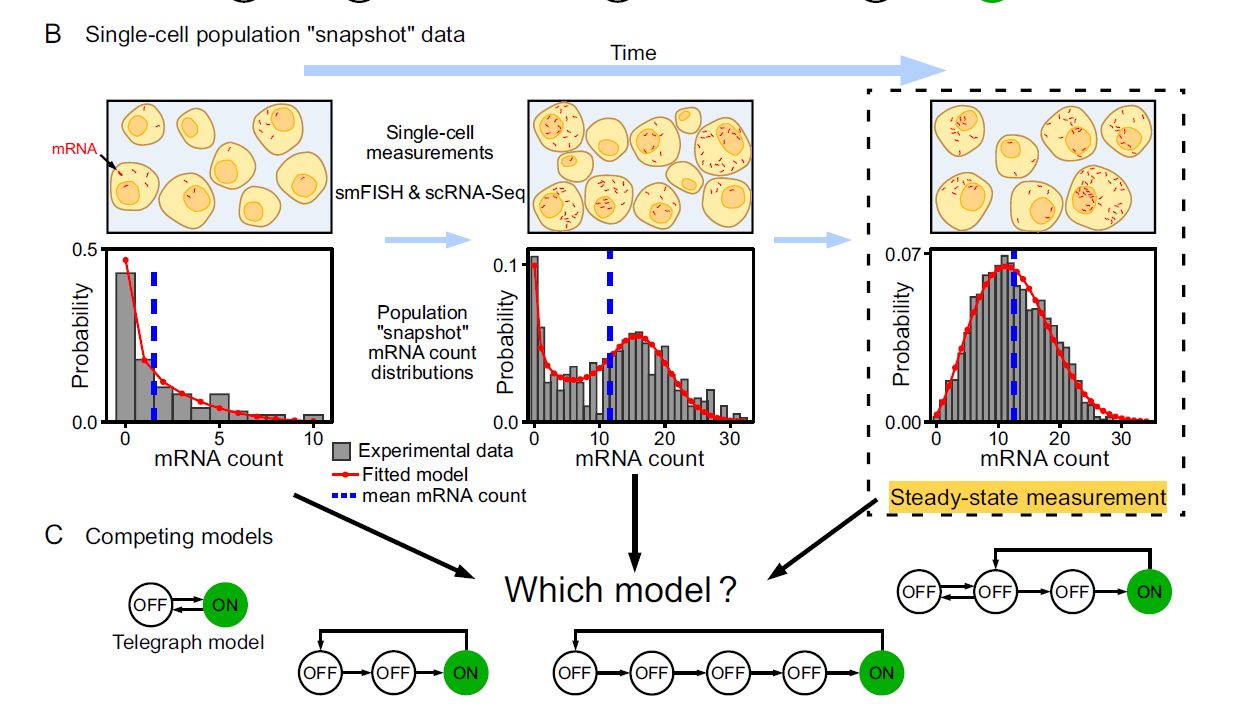
기존 학계는 steady-state의 mRNA count에 대한 PDF(probability density function)를 이용해서 유전자 발현의 rate-limiting step의 수를 알아내려고 했다. 그러나 저자들은 이런 방식이 엉터리라는 것을 수학적으로 증명하고 시뮬레이션으로 다시 증명한다.
왜냐하면, rate-limiting step이 1개인 model(telegraph model)의 parameter를 잘 조절하기만 하면, rate-limiting step이 2, 3, 4개인 다른 model이 만드는 steady-state mRNA count PDF를 거의 비슷하게 재현할 수 있기 때문이다. 저자는 생물학적으로 의미 있는 model의 99%는 telegraph model로 근사할 수 있다고 주장한다.
위 발견을 근거로, 저자는 rate-limiting step의 수를 알아내는 데는 steady-state에서의 정보가 쓸모없다고 말하며, 대신 시간에 따른 변화에 주목해야 한다고 주장한다. 그리고 본인들은 시간에 따라 변화하는 mRNA 농도의 평균값에 주목한다. 평균값을 사용하는 것의 이점은 PDF보다는 extrinsic static noise에 robust하다는 점이다. 여기서 extrinsic static noise는 세포 각각의 vitality(생생히 살아있어 mRNA를 잘 만드는 정도)의 variation이라고 생각하면 좋겠다.
이 시간에 따른 함수의 power-law exponent가 rate-limiting step의 최솟값을 알려준다는 것을 증명한다. 먼저 chemical master equation을 풀어서 t=0 이후 짧은 시간 동안 함수의 leading term이 power-law임을 보였으며, chemical network를 시뮬레이션하여 power-law exponent가 정말로 rate-limiting step의 수만큼 나온다는 것을 보였다.
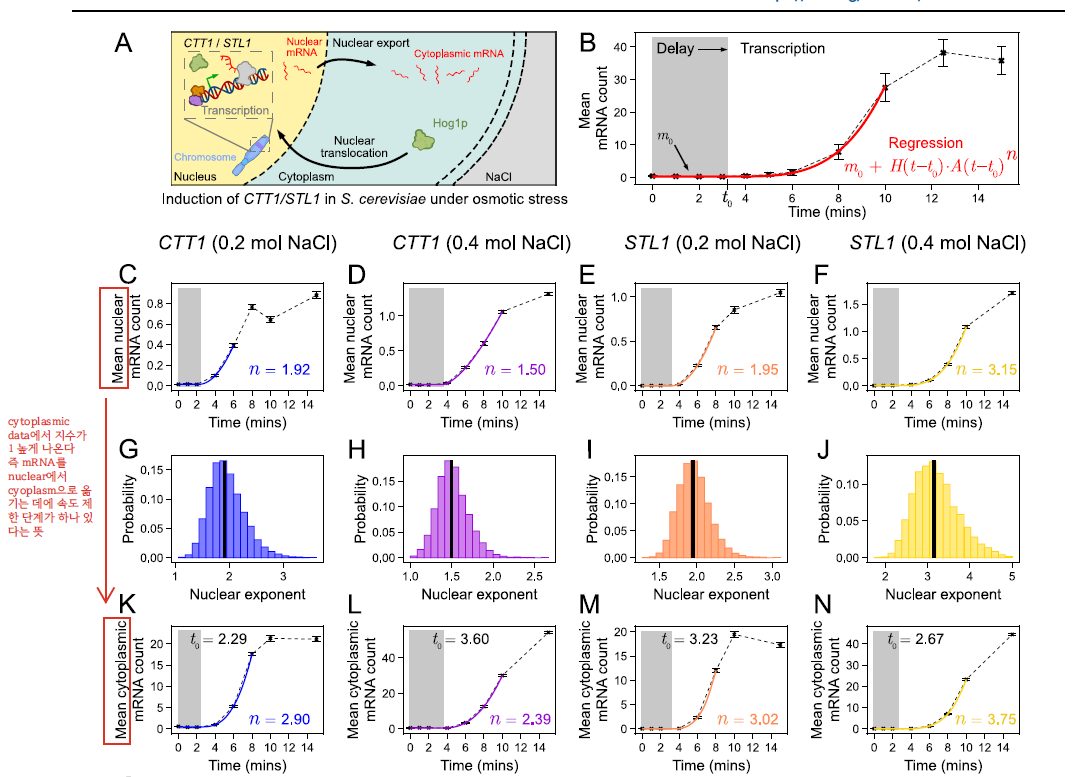
마지막으로 실제 생물학 실험 데이터에 fitting했다. 효모에 osmotic stress를 주어서 두 가지 유전자의 mRNA 수를 센 데이터를 사용했다. Nucleus에서의 mRNA 데이터와 cytosol에서의 mRNA 데이터를 따로 사용했다. 저자들의 가설이 맞다면, nucleus에서 cytosol로 mRNA를 옮기는 과정은 rate-limiting step으로 작용하기 때문에, 두 데이터에서 구한 power-law exponent는 cytosol에서가 nucleus에서보다 적어도 1 커야 한다. 그리고 진짜로 그렇게 나옴을 보였다.
Link to PDF and DOI
- DOI: 10.1038/s41467-025-58127-4
- PDF: Transient power-law behaviour following induction distinguishes between competing models of stochastic gene expression.pdf
- Supplementary: S - Transient power-law behaviour following induction distinguishes between competing models of stochastic gene expression.pdf
주요 내용 요약
notation

1. Limitation of steady-state mRNA conunt distribution data
steady-state mRNA conunt distribution 만으로는 N-state 모델(N=2,3,4,5)을 구별할 수 없다. 왜냐면 99%의 N-state model이 만드는 steady-state mRNA count distribution은 telegraph model이 근사할 수 있기 때문이다.
저자들은 이를 수학적으로 증명했다. N-state model에서 인접한 mRNA transcription 사이 시간 간격
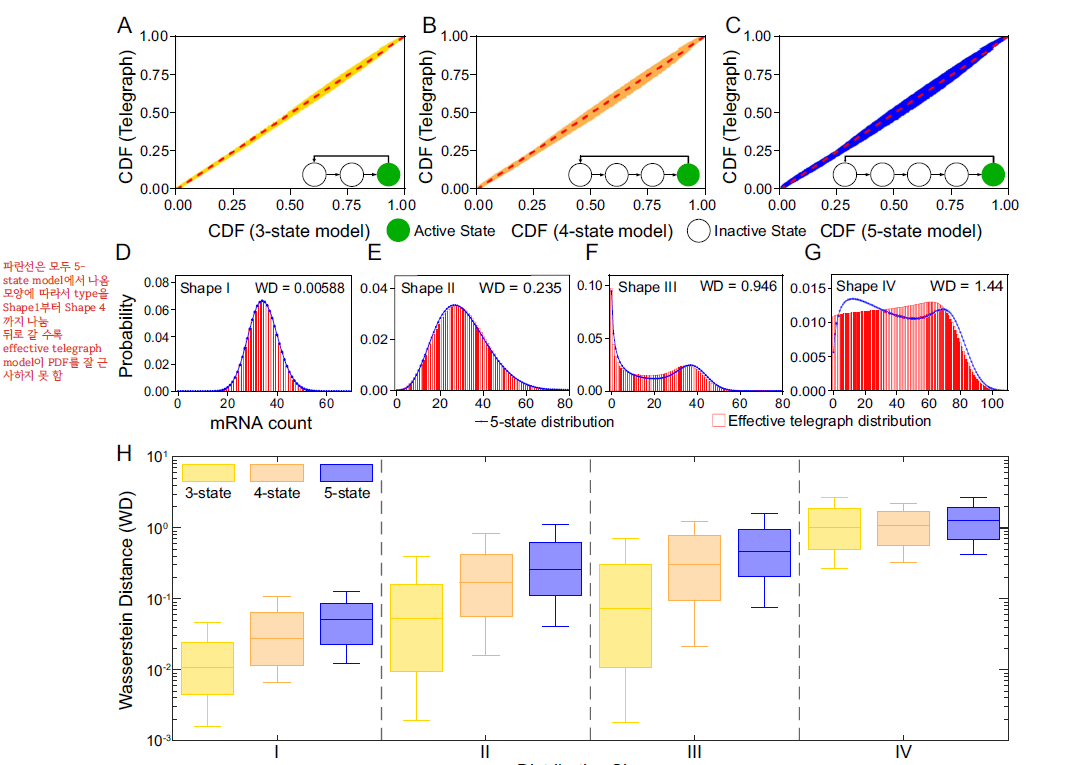
FIG 2 D, E, F, G를 보면 얼마나 잘 근사하는지 알 수 있다. 빨간 건 근사시킨 effective telegraph model의 steady-state mRNA distribution이고, 파란 선은 원본이 되는 5-state model의 것이다. Shape 4를 제외하고는 잘 맞춘다.
저자들은 Shape 4가 나오는 케이스는 생물학적으로 희소하다고 말하며, 그러므로 대부분의 경우는 telegraph model이 모든 N-state model의 steady-state mRNA distribution을 근사할 수 있다고 결론내린다.
2. 멱함수 법칙 발견
저자들은 chemical master equation을 풀어서
여기서:
: 총 유전자 상태 수 : 초기 비활성 상태 : power-law exponent - 이 지수는 전사 개시의 속도 제한 단계 수의 하한(lower bound)을 제공한다. 왜 하한이냐면 j가 무슨 값인지 모르기 때문이다.
chemical master equation simulation을 통해서 의도한 대로 power law exponents가 나오는 걸 보였다.
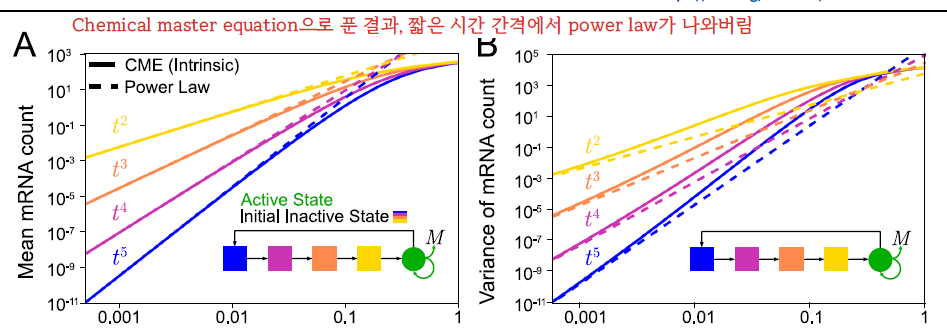
Fig3 A에 주목,
노란 건 2-state model, 주황색은 3-state model, 보라색은 4-state model, 파란색은 5-state model이다.
3. 실험 검증
효모(S. cerevisiae) 데이터 분석:
- 효모에게 osmotic stress를 주었을 때 CTT1, STL1 gene의 mRNA count data를 분석했다.
- 핵 내부와 핵 외부(cytoplasmic mRNA)에서 mRNA data를 따로 분석했다. 그 이유는 mRNA를 핵 안에서 핵 밖으로 옮기는 과정이 하나의 rate-limitting step일 것이므로, power-law exponent를 구하면 핵 밖에서가 핵 내부보다 적어도 1 은 거야 하기 때문이다.
- 확인해 보니 실제로 exponent가 핵 밖에서 1정도 크게 나왔다.
4. 이론적 확장
- 정적 외부 잡음(static extrinsic noise)에 강건함: 세포 간 파라미터 변동이 있어도 지수는 불변이다. mRNA count distribution은 noise에 변동이 심하다는 걸 고려하면, 이는 큰 장점이다.
- 복잡한 네트워크로 확장 가능: 가역 반응, 재개시(reinitiation), promoter-proximal pausing 등 포함
- 전사 후 과정 정보: 스플라이싱, 핵 수송, 번역 등의 속도 제한 단계 수도 구별 가능
Questions & Insights
-
Q: 지수 3.15를 설명하는데 왜 최소 N=4가 필요한가? j=1이면 N=3으로 충분하지 않나?
A: 순수 이론(Eq. 3)으로는 N=3이면 충분하다. 하지만 논문은 Figure 4의 시뮬레이션 결과를 사용한다. 생물학적으로 현실적인 시간 범위(수 분~수십 분)에서 데이터를 적합하면, 고차 항들의 기여로 인해 측정 지수가 이론 지수보다 작게 나온다. Figure 4G(N=4, j=1, 이론 지수=4)의 박스플롯을 보면 실제 적합 지수의 중앙값이 ~3 정도이다. 따라서 측정 지수 3.15는 실제 N=4를 시사한다. -
Q: 식 (12)의 첫 번째 등호는 왜 성립하는가?
A: 이것은 **Laplace 변환의 초기값 정리(Initial Value Theorem)**이다. 일반적으로가 성립한다. 직관적으로, 일 때 는 에서 급격히 0으로 가므로, 적분 는 근처의 기여만 남는다. 더 정확히는, 가 일 때 Dirac delta처럼 작동한다: (분포 의미에서). 이는 delta 수열의 한 예로, 높이는 로 증가하고 폭은 로 감소하면서 면적은 1로 유지된다. 두 번째 등호 는 물리적 의미를 가진다: 대기 시간이 0일 확률 밀도는 곧 전사율 와 같다. 이는 활성 상태 N에서 즉시 다시 전사가 일어날 “순간 속도”를 나타낸다.
Related Concepts
더 읽어보고 싶은 레퍼런스
이 논문을 인용한 다른 논문을 찾아 읽어보고 싶다.